El componente técnico
El componente técnico del sistema de detección de programas nocivos se ocupa de reunir los datos que se utilizarán para el análisis de la situación.
Un programa nocivo es, por una parte, un fichero con un determinado contenido; por otra parte es un conjunto de acciones que se efectúan en el sistema operativo; y en tercer lugar, el conjunto de efectos resultantes en el sistema operativo. Por esto, la identificación de estos programas puede hacerse a varios niveles: según las cadenas de bytes, según sus acciones, según sus efectos en el sistema operativo, etc.
Generalizando, se pueden aislar los siguientes métodos de recolección de datos para desenmascarar a los programas nocivos:
- tratar al fichero como un conjunto de bytes;
- emular1 el código del programa;
- ejecutar el programa en un “espacio aislado” (Sandbox2), utilizar tecnologías de virtualización similares;
- monitorizar los eventos del sistema;
- buscar anomalías en el sistema;
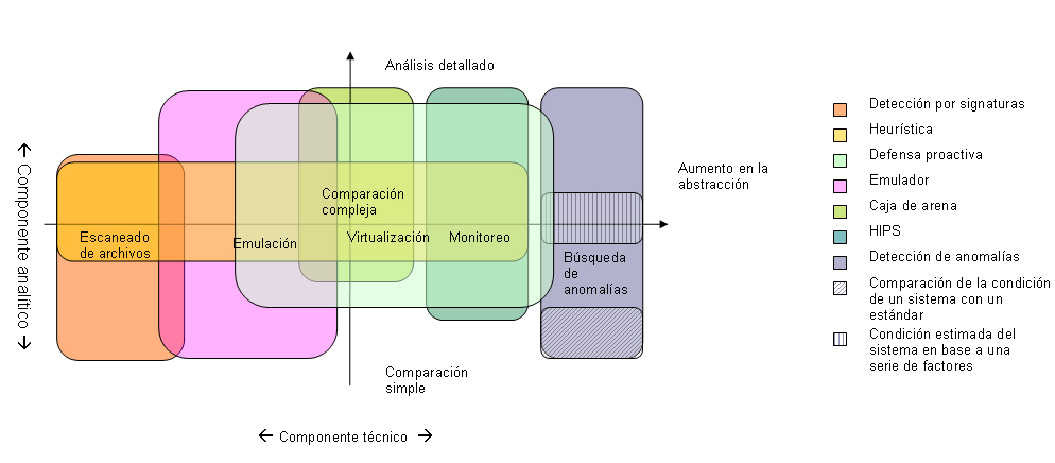
Hemos enumerado estos métodos según el nivel de abstracción durante su trabajo con el código. En este caso entiendo como nivel de abstracción el punto de vista con el que se analiza el programa ejecutable: como objeto digital primario (conjunto de bytes), como comportamiento (una consecuencia más abstracta del conjunto de bytes) o como un conjunto de efectos en el sistema operativo (una consecuencia más abstracta del comportamiento). El desarrollo de las tecnologías antivirus también siguió el mismo vector: primero el trabajo con ficheros, luego con eventos a través de ficheros, después con ficheros a través de eventos, a continuación el trabajo directo con el sistema operativo. Esta es la razón por la que la lista aducida aquí de forma natural tomó un orden cronológico.
Hago hincapié en que los métodos mencionados no son tanto tecnologías aisladas, sino más bien etapas convencionales del proceso ininterrumpido del desarrollo de las tecnologías de recolección de datos para la detección de programas nocivos. Las tecnologías se desarrollan para convertirse en otras y lo hacen de forma más o menos gradual. Por ejemplo, la emulación puede estar más cerca al punto (1) si su realización en un caso dado sólo transforma parcialmente el fichero como un conjunto de datos, o puede estar más cercana al punto (3) si se trata de una virtualización total del sistema de funciones.
Estudiaremos estos métodos de forma más detallada.
Lectura de ficheros
Los primeros antivirus se basaban en el análisis del código de los ficheros en cuanto conjunto de bytes. Pero no es muy apropiado llamar "análisis" a este proceso: se trata de una simple comparación de una sucesión de bytes con una firma conocida (que también es una sucesión de bytes). En este momento lo que nos interesa es el aspecto técnico de la tecnología descrita, a saber: durante el proceso de búsqueda de programas nocivos los datos que se transmiten al componente que tomará las decisiones se extraen de los ficheros y son un bloque de bytes ordenados de cierta forma.
La peculiaridad que tiene este método es que el antivirus trabaja sólo con el código de bytes original del programa, sin tocar su comportamiento. A pesar de que este método es arcaico, no ha caído en desuso y, de una forma u otra se usa en todos los antivirus modernos, pero ya no como método principal, sino como uno de varios.
Emulación
La tecnología de emulación es un escalón intermedio entre el procesamiento de un programa en cuanto conjunto de bytes y su procesamiento en cuanto secuencia de determinadas acciones.
El emulador divide el código de bytes del programa en instrucciones y ejecuta cada una de éstas en un ordenador virtual. Esto permite al programa de defensa observar el comportamiento del programa nocivo sin poner bajo peligro el sistema operativo y los datos del usuario, lo que inevitablemente ocurriría al ejecutar el programa nocivo en un sistema operativo real.
El emulador funciona como un estadio intermedio de abstracción durante el trabajo con el programa. Por esta razón, la particularidad determinante del emulador se podría formular a grandes rasgos de la siguiente manera: el objeto de trabajo del emulador sigue siendo el fichero, pero de hecho en éste se analizan eventos. Los emuladores se usan en muchos (quizás en todos) los grandes antivirus, sobre todo como complemento al motor de detección de nivel más bajo o como una forma de reforzar los motores de detección de nivel más alto (como el de "medio virtual" o la monitorización del sistema).
Virtualización: entornos virtuales
La virtualización usada en los “entornos virtuales” es la continuación lógica de la emulación. Es decir: el “entorno virtual” ya trabaja con un programa que se ejecuta en un medio real, pero todavía lo controla.
La esencia de esta virtualización se refleja muy bien en el nombre de la tecnología “sandbox” (medio virtual). En la vida real, el termino inglés “sandbox” es un espacio aislado donde lo niños pueden jugar sin peligro. Si hacemos una analogía y entendemos que el mundo real corresponde al sistema operativo y los traviesos niños al programa nocivo, entonces como “corralito” podríamos entender un conjunto de reglas de interrelación con el sistema operativo. Las reglas pueden prohibir la modificación del registro del SO o limitar las operaciones con el sistema operativo mediante su emulación parcial. Por ejemplo, al programa que se ejecute en el “medio virtual” se le puede “ofrecer” una copia virtual del registro del sistema, para que los cambios que el programa introduzca en el registro no puedan influir en el funcionamiento del sistema operativo. De esta manera se puede virtualizar cualquier punto de contacto del programa con el medio: el sistema de archivos, el registro, etc.
El límite entre la emulación y la virtualización es muy delgado, pero tangible. La primera tecnología brinda un medio para ejecutar programas y, de esta manera, durante su funcionamiento la contiene y controla completamente). En el segundo caso, el papel de medio lo cumple el sistema operativo en sí, y la tecnología sólo controla la interacción entre el sistema operativo y el programa. A diferencia de la emulación, la virtualización está en igualdad de condiciones con el programa que se ejecuta.
Así, el medio de defensa basado en una virtualización de este tipo trabaja ya no con el fichero, sino con el comportamiento del programa, pero todavía no con el sistema.
El mecanismo del “medio virtual”, al igual que el emulador, no se usa mucho en los antivirus, sobre todo porque su realización en software requiere de una gran cantidad de recursos. Los antivirus que contienen un “medio virtual” son fáciles de identificar por el retraso que provocan entre el lanzamiento del programa y el inicio de su ejecución (o en caso de detectarse un programa nocivo, entre su lanzamiento y la notificación que da el antivirus sobre la detección). Tomando en cuenta que en la actualidad se están efectuando activamente investigaciones en el campo de la virtualización hardware, la situación puede cambiar pronto.
Por el momento el motor de detección tipo “sandbox” se usa en sólo algunos antivirus.
Monitorización de los eventos del sistema
La monitorización de los eventos que ocurren en el sistema es un método más abstracto de recolección de información útil para la detección de los programas nocivos. Si el emulador o “sandbox” observan cada programa por separado, el monitor hace un seguimiento de todos los programas al mismo tiempo mediante la protocolización de todos los eventos que ocurren en el sistema operativo y que son provocados por los programas en funcionamiento.
Desde el punto de vista técnico, este método de recolección de información se realiza mediante la intercepción de las funciones del sistema operativo. De esta manera, al interceptar una llamada de alguna función del sistema, el mecanismo de intercepción recibe información de que un programa determinado ejecuta cierta acción en el sistema. Durante su trabajo, el monitor hace una estadística de estas acciones y las envía al componente analítico para su procesamiento.
Este principio tecnológico es el que se está desarrollando más activamente en el presente. Se lo utiliza como uno de los componentes en los grandes antivirus y como fundamento en los utilitarios que se especializan en la monitorización del sistema (denominados “utilitarios HIPS”, como Prevx, CyberHawk y otros más). Pero si se toma en cuenta que cualquier defensa es vulnerable, este método de búsqueda de programas nocivos no nos parece el más efectivo, ya que al ejecutar un programa en un entorno real, el riesgo reduce de forma sustancial la efectividad de la defensa.
Búsqueda de anomalías en el sistema
Este es el método más abstracto de recolección de información sobre un sistema que se supone infectado. Lo menciono aquí en primer lugar como continuación lógica y límite de abstracción en la lista de tecnologías.
Este método se basa en los siguientes supuestos:
- el sistema operativo junto a los programas que se ejecutan en el mismo es un sistema integral;
- le es inherente cierto “estado del sistema”;
- si en este entorno se está ejecutando un código nocivo, el estado del sistema se considera “enfermo” y se diferencia del estado "saludable" de un sistema que no contiene código nocivo;
Partiendo de estos supuestos, podemos emitir un juicio sobre el estado del sistema (y, en consecuencia, sobre la posible presencia de programas nocivos), comparándolo con un patrón o analizando el conjunto de algunos de sus parámetros.
Para que la detección del código nocivo mediante el método de análisis de anomalías sea efectiva, es imprescindible contar con un sistema analítico bastante complejo, similar a los sistemas de expertos o a las redes neuronales. Surgen muchas preguntas: ¿cómo determinar el “estado saludable”?¿en qué se diferencia del “enfermo"?; ¿qué parámetros hay que observar y cómo analizarlos? Debido a estas dificultades, en la actualidad este método está poco desarrollado. Ciertos rudimentos del mismo se pueden observar en algunos utilitarios anti-rootkit, donde están plasmados al nivel de comparación con determinado "estado" del sistema que se toma como patrón (obsoletos en la actualidad como PatchFinder o Kaspersky Inpector), o con determinados parámetros (GMER, Rootkit Unhooker).
Una metáfora divertida
La analogía con el bebé que juega en un espacio aislado se puede continuar de la siguiente manera: el emulador se parece a una niñera que cuida constantemente al bebé, para que éste no cause desastres; el monitor del sistema es como un educador que vela por todo un grupo de niños; la búsqueda de anomalías en el sistema sería como conceder total libertad a los niños, con la única limitación impuesta por el control de sus calificaciones en su cuaderno de notas. En este caso el análisis de los bytes del fichero es similar a la "planificación" del bebé, es decir, la búsqueda de indicios que indiquen predisposición a las travesuras en el código genético de sus padres.
Al igual que los individuos, las tecnologías crecen y se desarrollan.
El componente analítico
El grado de refinamiento del algoritmo de toma de decisiones es una característica continua. Puede ser el que se quiera. Muy condicionalmente se pueden dividir los sistemas analíticos de los antivirus en tres categorías, entre las cuales puede haber muchas variantes intermedias.
Comparación simple
El veredicto se pronuncia según los resultados de la comparación de un objeto con el modelo de que se dispone. El resultado de la comparación es binario (“sí” o “no”). Ejemplo: identificación de un código nocivo según una secuencia determinada de bytes. Otro ejemplo, de nivel más alto: la identificación del comportamiento sospechoso del programa por un único criterio de las acciones que realiza (por ejemplo, escribir en un sector crítico del registro o en la carpeta de "Autoinicio").
Comparación compleja
El veredicto se pronuncia según los resultados de la comparación de uno o varios objetos con las muestras correspondientes. Los patrones de comportamiento pueden ser flexibles y el resultado de la comparación, probable. Ejemplo: la identificación del código nocivo según una de varias firmas de bytes, cada una de la cuales no es rigurosa (por ejemplo, no se han definido unívocamente determinados bytes). Otro ejemplo, de nivel más alto: la identificación del código nocivo según varias funciones API usadas o llamadas con determinados parámetros.
Sistema de expertos
El veredicto se emite como resultado de un delicado análisis de los datos. Este puede ser un sistema que contenga rudimentos de inteligencia artificial. Ejemplo: la identificación de un código nocivo no se realiza según un conjunto establecido de parámetros, sino por el resultado de la apreciación multilateral de los parámetros en general, asignando a cada uno de los eventos cierto peso de “nocividad potencial” y con el cálculo del resultado final.